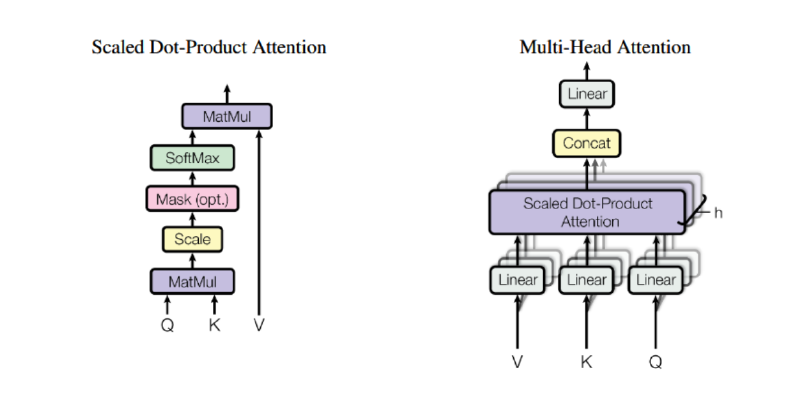
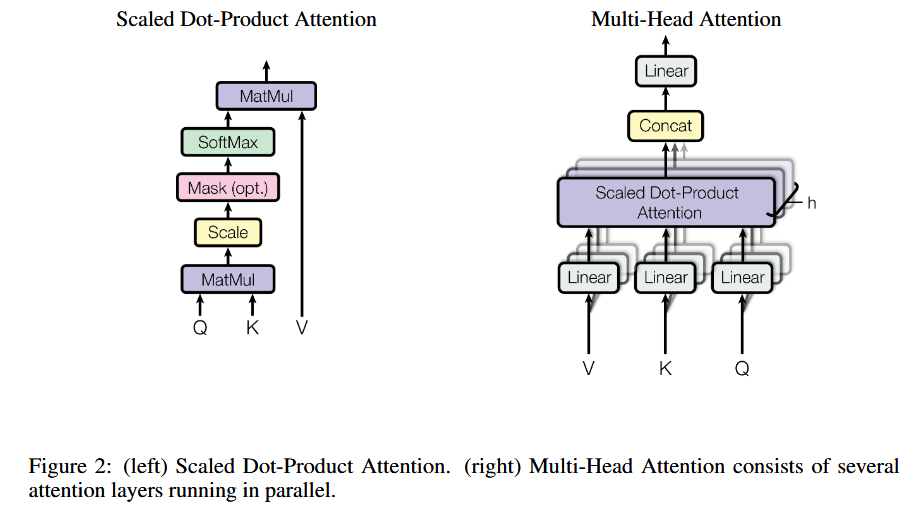
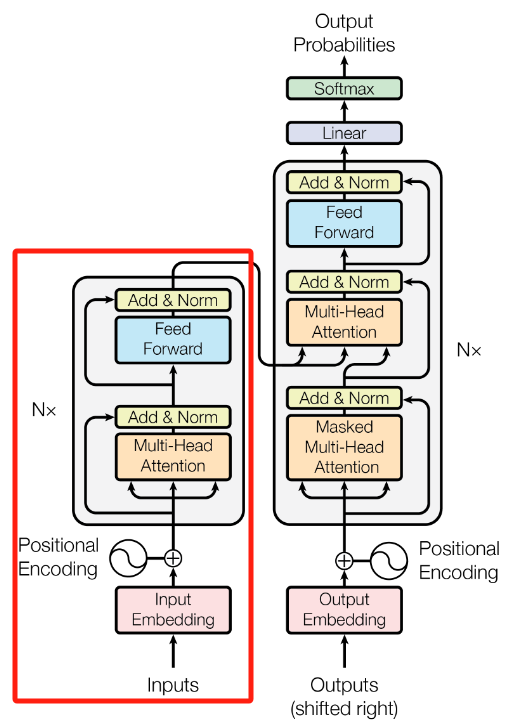
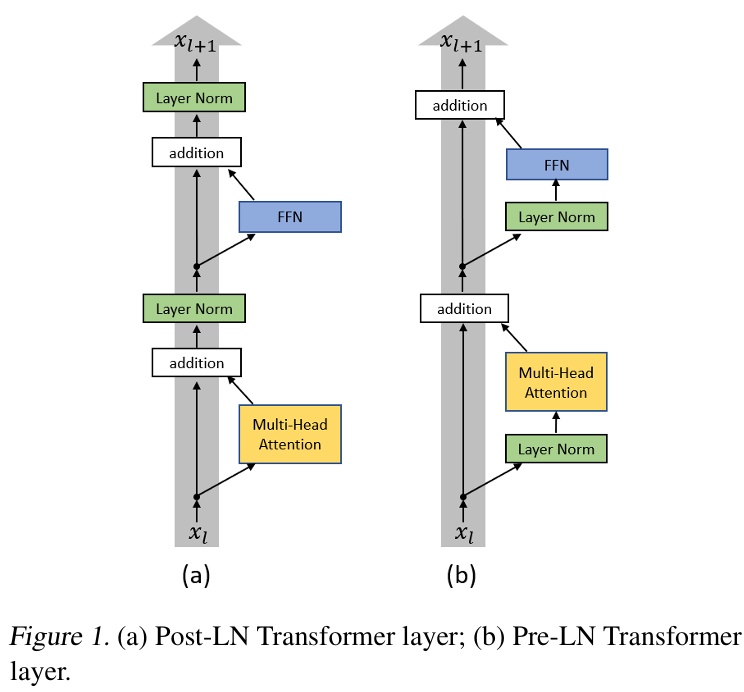
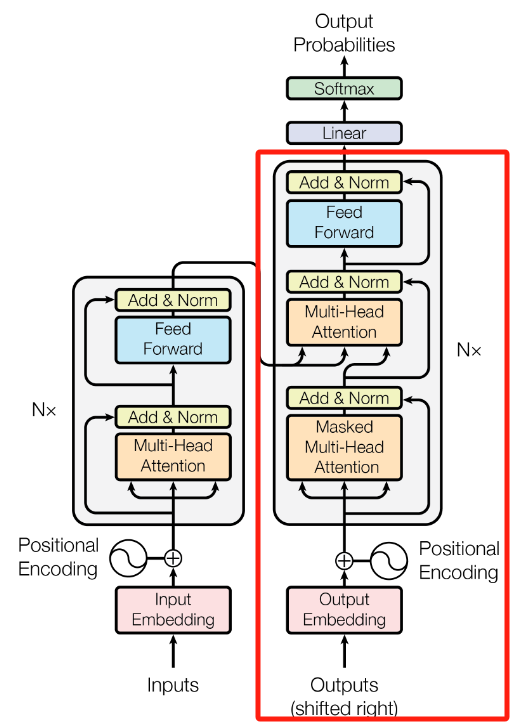
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
| import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
def scaled_dot_product_attention(query, key, value, mask=None):
dim_k = key.size(-1)
attn_scores = torch.bmm(query, key.transpose(1, 2)) / np.sqrt(dim_k)
if mask is not None:
attn_scores.masked_fill_(mask == 0, float('-inf'))
attn_weights = F.softmax(attn_scores, dim=-1)
attn_outputs = torch.bmm(attn_weights, value)
return attn_outputs
class AttentionHead(nn.Module):
def __init__(self, embed_dim, head_dim):
super().__init__()
# Learnable Parameters
self.Wq = nn.Linear(embed_dim, head_dim)
self.Wk = nn.Linear(embed_dim, head_dim)
self.Wv = nn.Linear(embed_dim, head_dim)
def forward(self, query_input, key_value_input, mask=None):
# Project Q
q = self.Wq(query_input)
# Project K
k = self.Wk(key_value_input)
# Project V
v = self.Wv(key_value_input)
attn_outputs = scaled_dot_product_attention(q, k, v, mask)
return attn_outputs
class MultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
embed_dim = config.hidden_size # 768
num_heads = config.num_attention_heads # 12
head_dim = embed_dim // num_heads # 64
self.heads = nn.ModuleList([
AttentionHead(embed_dim, head_dim) for _ in range(num_heads)
])
# 768 -> 768
self.output_layer = nn.Linear(embed_dim, embed_dim)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, query_input, key_value_input, mask=None):
x = torch.cat([head(query_input, key_value_input, mask) for head in self.heads], dim=-1)
x = self.output_layer(x)
x = self.dropout(x)
return x
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
# (intermediate)
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
# (output)
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states):
hidden_states = self.fc1(hidden_states)
hidden_states = self.gelu(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.fc2(hidden_states)
return hidden_states
class TransformerEncoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.attention = MultiHeadAttention(config)
self.ffn = FeedForward(config)
self.layernorm1 = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.layernorm2 = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states):
attn_output = self.attention(hidden_states, hidden_states)
hidden_states = self.layernorm1(hidden_states + attn_output)
ffn_output = self.ffn(hidden_states)
hidden_states = self.layernorm2(hidden_states + ffn_output)
return hidden_states
class TransformerDecoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.self_attn = MultiHeadAttention(config)
self.cross_attn = MultiHeadAttention(config)
self.ffn = FeedForward(config)
self.layernorm1 = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.layernorm2 = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.layernorm3 = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states, encoder_outputs, self_attn_mask=None, cross_attn_mask=None):
self_attn_output = self.self_attn(hidden_states, hidden_states, self_attn_mask)
hidden_states = self.layernorm1(hidden_states + self_attn_output)
cross_attn_output = self.cross_attn(hidden_states, encoder_outputs, cross_attn_mask)
hidden_states = self.layernorm2(hidden_states + cross_attn_output)
ffn_output = self.ffn(hidden_states)
hidden_states = self.layernorm3(hidden_states + ffn_output)
return hidden_states
class DummyConfig:
hidden_size = 768
num_attention_heads = 12
intermediate_size = 3072
hidden_dropout_prob = 0.1
layer_norm_eps = 1e-12
if __name__ == '__main__':
config = DummyConfig()
batch_size = 2
seq_len = 10
hidden_size = config.hidden_size
# 输入张量
dummy_input = torch.randn(batch_size, seq_len, hidden_size)
# 测试 Encoder Layer
encoder_layer = TransformerEncoderLayer(config)
encoder_output = encoder_layer(dummy_input)
print("Encoder Output Shape:", encoder_output.shape)
# 测试 Decoder Layer
decoder_layer = TransformerDecoderLayer(config)
decoder_input = torch.randn(batch_size, seq_len, hidden_size)
decoder_output = decoder_layer(decoder_input, encoder_output)
print("Decoder Output Shape:", decoder_output.shape)
|